The Project's Origins
Working professionally in the IT space, i'm
always trying to keep up with the latest technologies, and the
latest trends. It all started when i saw an interview with the CEO
of Microsoft, Satya Nadella, talking about the future of AI and
how it will change the work space as we know it. He was
specifically talking about AI Agents and how they eventually will
replace all SAS applications.
(For those interested heres the interview:
Satya Nadella on AI Agents)
I thought to myself "Wow that sounds like a bold statement" but i
hadn't really looked much into AI agents myself.
So, i decided to look into it and see what all the fuss was about.
I started to read about the latest tools and techniques, and how
these "AI Agents" work. I purchased a subscription to openAI and
started to play around with the API. I quickly discovered that
with just a few lines of python code i could create an AI agent
that could do simple tasks. I experimented with it for a few
hours, giving it a few simple tasks to complete, but lacked
inspiration to really leverage the full potential of the API.
That was until i gave it the simple prompt -- "Your are a pirate, write a short story of your adventures"
I was quite impressed with the results, from such a simple prompt!
This is when i really started experimenting!
Soon, before i knew it, i had created character profiles, back
stories, locations, world building, pirate lore, and a whole lot
more! I sat for hours reading the stories my agent was
telling me, and i was hooked!
Thats when i had the thought, "I wonder if other people would
enjoy these wacky stories as much as i have?"
I had been looking
for a creative project i could really sink my teeth into, and this
seemed like a fun idea!
and thus, the captains-journal was born.
Okay, heres what i'll do!
I'll whip up a quick HTML page, host it in an Azure static website, write some simple code, host the text episodes in a Azure blobs storage and voila!Right ?
errrr Right............... ?
mwahahha, Jake your poor little innocent flower, you have no idea what your about to get yourself into!
Humble Beginnings
Okay, so at this point i now have an AI agent that is convinced it's a captain of a pirate ship.It can now generate short stories in a text format, and output the .txt files locally on my machine.
This is cool, but i want to make a web series with daily episodes.
Currently the agent can generates a short pirate story, save it as a .txt file, but next time the scrpt runs, it generates a new story and overwirtes the current .txt file.
Okay, lets make some changes to the code!
Firstly, i need to update the agent itself.
Currently all the agent knows is, it is the captain of at pirate ship, and should tell short stories.
I want to update the agent to be able to generate a new episode every day, the new episode should be a follow-up to the previous episode. If the last eipsode is captains_log_1.txt the next episode should be captains_log_2.txt and so on.
I started by updating the prompt for the agent.

I then made a few changes to the python script
The script now scans the local directy where the "captaions_log_X.txt files are created. If the script finds captains_log_1.txt it will then produce captains_log_2.txt, and so on. If no .txt files are found, the script will create a new episode.
Okay, good start!
The agent is now able to generate a new episode every run, it also names the .txt file correctly, (Depending on if this is the first episode, or previous episodes exist) but the actual episodes and story telling is not consistant.
If i want to make a web series with daily episodes. For this to work, its extremely important that episdoes are consistant. Each episode should be a continuation of the previous one.
This won't work if the story arch keeps changing, characters are suddenly in different locations, doing different things etc...
hmmmm what if i could generate a new episode every day, each episode following the same consistent story arch?
Enter The Captains assistant!
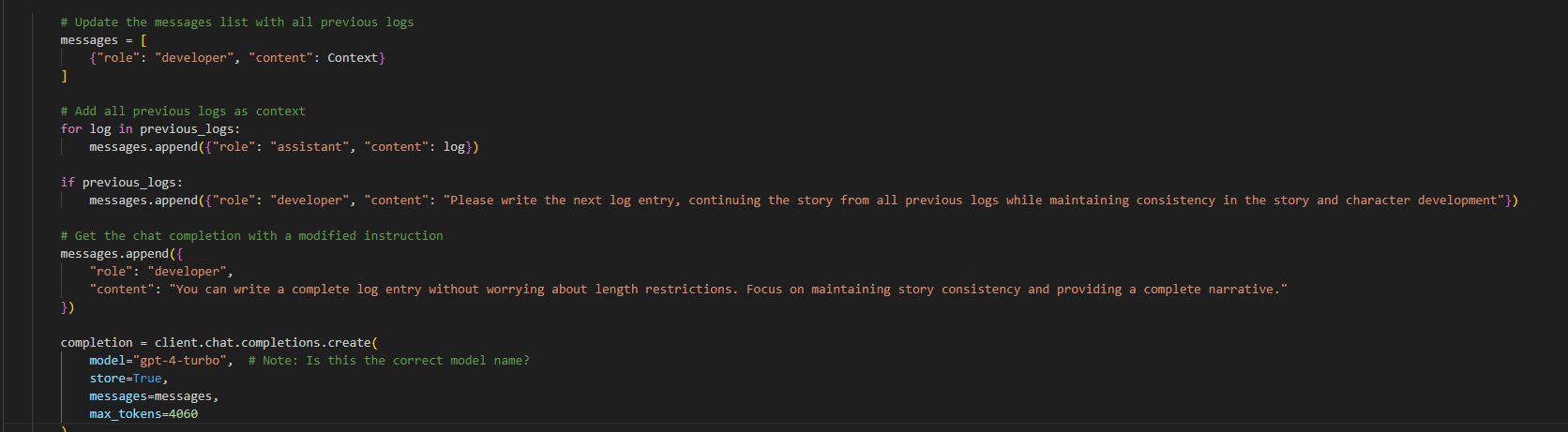
Okay, so i needed a way for the AI to keep track of the story, character arcs, locations visited, and especially what happened in the previous episode.I managed to achieve this by adding an assistant to the prompt.
The Assistant is responsible for reading all previous logs generated for the story so far.
So how does this work?
Just like like the main agent, the assistant first checks the local file directory for any existing .txt files. If any .txt files are found, the assistant then reads through all content and comits it to memory. The main agent then receives a new prompt, with the assistant's memory as the context.
In this case, if text files are found the agent will receive the prompt - "Please write the next log entry, continuing the story from all previous logs while maintaining consistency in the story and character development"
If no text files were found, the agent will receivve the prompt - "You can write a complete log entry without worrying about length restrictions. Focus on maintaining story consistency and providing a complete narrative."
I'm now able to generate consistent episodes that maintain a smooth and continuous story arc, ensuring each installment seamlessly connects to the next.
This allows for ongoing character development, engaging plot progression, and a more immersive storytelling experience.
Pretty cool right?
but, what if we didn't have to read the stories ourself?
The Voice of the Captain
This is where things start to get really interesting. (and also a little wacky 😂)I'm now able to generate a new episode every run, with a continous story arch, characters, locations, and a continous story. but it's just text.....
what if i could generate a audio version of each episode?
Okay, time to hit the "Google-kung-fu" lets see what options i have!
Oh snap! OpenAI has a text to speech API! OpenAI Text to Speech API
Okay lets see what we can build!
After reading through the documentation it was actually pretty quick and easy to get a prototype up and running.
I went with the voice "Ash" as i felt this was the voice that sounded best for a narrator. However, i wansn't 100% happy with the voice, so i deciced to experiment a bit, and this is where things get a bit wacky 😂
First i tried cloneing my own voice, and creating an AI version of myself to read the text. This actually worked better than i expected, which made it all the more creepy!
One thing is listening to your own voice, but listening to yourself say things you've neveer said, or read words completely different to how you would normally read them, was just a little to weird for me.
It also tried to make me sound waaaaaaaaaaaaay posher then i am, which again, doesn't really work for a pirate story.
For those interested - here is a little preview of AI Jake!
Jake the Narrator
Next up, i dawned my pirate hat and eyepatch, and attempted to make a pirate AI voice.
This was achieved by reading a bunch of text in my best pirate voice. Needless to say, this evening i got alot of strange looks from my better half, as i sat yelling pirate slurs to myself for a good couple of hours.
This it what It ended up producing😂😂
Jake the Pirate
As i sit writing this blog, i'm still not entirely sure what voice i'm going to go with for the finished product. I still have alot of experimentation to do with different API's and prodcuts, so i guess you'll have to wait and see!
Token Drama
4096, a number that probablly doesn't mean anything to most people, but to me it was a number i needed to overcome!So what is this mysterious number 4096 you ask? - 4096 is the "token limit" for any OpenAI API reponse.
What this means is, the maximum output for each openAI API call can not exceed 4096 tokens.
Okay, so what the hell is a a "Token" ? and how are they calculated?
Tokens are calculated by the number of words in the text. Tokens are pieces of words or characters that the AI processes to understand and generate text.
They are not the same as words but represent fragments of words, whole words, or even punctuation.
In English, 1 token ≈ 4 characters (on average).
A single word can be multiple tokens, especially if it's complex.
Short words like "a" or "is" count as 1 token.
Longer words like "artificially" may be split into multiple tokens.
For example:
"Hello" = 1 token
"Captains" = 1 token
"Extraordinary" = 2 tokens
"Pirate's adventure!" = 4 tokens
"The treasure is near." = 5 tokens
Since 1 token is, on average, 4 characters in English, and the average English word is around 5 characters long (including spaces), we can estimate that an output of 4096 tokens would contain roughly 3280 words.
At a normal narration pace of 130 words per minute, this would translate to about 25 minutes of audio. (According to ChatGPT)
Wait a second! Why are my audio files only around 3 and a half minutes long ?!?!
Is my maths completely off? or is something else going on her?
Errrmmm..... i'll be right back, i need to figure out whats going on! (Yes i'm finding this out now as i write this blog)
Oh hi there! Im back!
Sure, for you, it's like i never left, but i've actually been gone for hours, yup, thats right, hours! Another rabit hole into the depth of AI.
but hey! I learnt some stuff when i was gone.... wanna hear it ?
Okay heres the deal..... Turns out there is a direct correlation between the number of tokens in the input and the output.
How Input Size Affects Output
GPT-4 Turbo has a max context length of 128k tokens (input + output combined).
Output tokens are capped at 4096 per request (this is a separate limitation).
The more input tokens you use, the fewer output tokens are available.
Allthough this is a limitation first kicks in after 120k tokens.
| Input Size (Tokens) | Max Possible Output (Tokens) |
|---|---|
| 1,000 | 4,096 ✅ (Full response possible) |
| 3,000 | 4,096 ✅ (Full response possible) |
| 10,000 | 4,096 ✅ (Still full output possible, as long as the total stays under 128k) |
| 120,000 | 8,000 ⚠️ (Limited output tokens remaining) |
| 125,000 | 3,000 ⚠️ (Very limited output tokens remaining) |
| 127,000 | 1,000 ⚠️ (Critically low output tokens remaining) |
| 128,000 | 0 ❌ (No room for output! Model won't generate anything) |
Oh dear, maybe i'm using to many tokens in my input, and thats the reason my output is so short?
Okay back to coding, there must be a way to get an overview of the token usage.
Alright cool, manged to setup some code to monitor token usage, lets run some tests and see how we're looking!

Okay according to my logs, i'm not even close to hitting 120k tokens (Which is the point where output limits would start to accour).
As you can see on the above screenshot, my prompt is only using 5035 tokens (This test was done generateing the third episode in a on-going saga, so there ware 2 previous logs that needed to be loaded to memory, these logs were at total of 1486 tokens)
Giving us a grand total of 6033 tokens.
So what exactly is happening here?
Honestly i'm not exactly sure, but i do know, i'm not using anywehre near 120k tokens on my input. From what i can tell, the agent maybe just feels that the entry it has given is adequate, and doesn't need to add any more detail.
Prehaps i'm overcomplicating things. Maybe i should tell the agent to make each story be 4095 tokens in length.

At the same time i also updated the code to actaully display the toke size of the output. (Ouput tokens)
Lets see how this works!
Test 1:

Test 2:
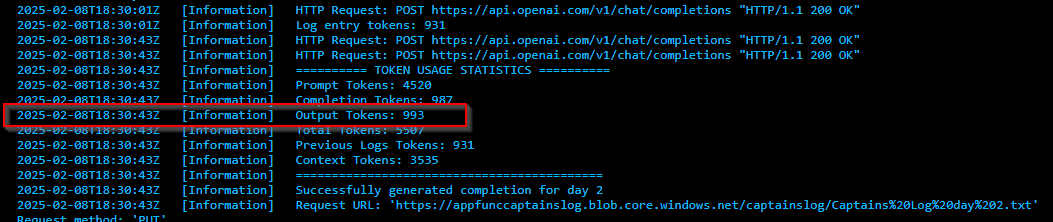
Wow, not even close to 4096! I'm not evening close to hitting the input limit, or the output limit.
It also completely ignored the fact i told it specifically to use all 4096 tokens.
Just to elaborate, it's not that i want it to output exactly 4096 tokens each time, that would be way to long for a daily episodeic adventure, but i definitely want more than 933 tokens..
Alright back to the drawing board, time to read up on the OpenAI documentation *AGAIN* and see if i can find anything else that can help me out.
Okay, turns out there is something called a"Stop_reason" parameter in the API.
Seems there can be mutiple reasons why the model may stop generating content.
*stop* = The Model chose to stop early
*length* = The Model hit the max token limit
*content_filter* = OpenAI blocked part of the output
*null* = The Model stopped but no reason given
Again, time to add more dedugging and logging to the code, lets see if we can find the reason why the model is stopping.

WELL SON OF A BITCH! IT JUST STOPPED, "BECAUSE IT FELT LIKE IT", EVEN THOUGH DADDY SPECIFICALLY SAID "GIVE ME 4096 TOKENS"
Okay lets try giving it the stop=none parameter - This means the model *should* not stop no matter what.
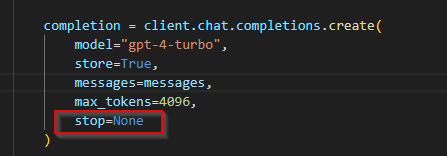
We'll also give it a little more convincing via a new prompt.

YOU OW ME 4096 TOKENS, AND DADDY WANTS HIS TOKENS! - Just like Brad pit wants his scalps...
(This is Inglorious bastards reference, if you haven't seen the film, stop reading this blog and go watch it NOW!)
Did you watch it ?
Amazing right? Quentin Tarantino really is a genius!
eeerr,, ummm.. anywaaaaayyyyyy.... Where were we?
Ah yes, the disobedience of my creation!
Lets try run the model again with the new improved prompt.

Disobeyed by my creation once again... 1161 tokens....
"Cocks Shotgun"
Iv'e played with this for a few hours now, and i'm not able to get the model to ouput anywhere near to 4096 tokens, no matter how hard i try. I have however managed to get longer outputs in general. I'm now averaging around 1200 tokens per episode, which is around 5 minutes of audio, so that's a slight improvement.
One thing i have noticed however, is that the model seems to generate longer and longer outputs as the series goes on.
I'm presuming this is probably because i'm constantly feeding the model with the previous episodes, giving it more and more data to work with.
So presumably, the series will get more and more detailed as it goes on.
I may re-vist this later, but for now i'm going to focus on the next set of problems.
Temperature
Before I completely move on from this token drama, I'd like to touch quickly on the "Temperature" parameter, as this can essentially also effect the output length.
Temperature is a key setting in AI models (like GPT-4 Turbo) that controls how random or predictable the AI's responses are. It affects the creativity, coherence, and unpredictability of the output.
The temperature parameter is a float between 0 and 1.
🔥 How Temperature Works
Low Temperature (0.1 - 0.4) → More Predictable, Logical Responses
- The AI sticks to safer, more deterministic answers
- Good for technical, fact-based, or structured tasks
- Example: AI follows strict patterns and rarely improvises
Medium Temperature (0.5 - 0.7) → Balanced Responses
- A mix of coherence and creativity
- Ideal for storytelling, brainstorming, and engaging conversations
- Example: AI follows logical structures but adds some variation and personality
High Temperature (0.8 - 1.2) → Wild, Creative, Unpredictable
- The AI takes risks and improvises more
- Great for jokes, poetry, and wacky storytelling
- Example: AI generates surreal, chaotic, or unexpected responses
🎭 How Temperature Affects a Pirate AI
Let's say we ask the AI: "What does a pirate say when he finds buried treasure?"
🚨 Low Temperature (0.2)
"Arrr, we found the treasure! Let's take it back to the ship."
(Boring, expected, factual.)
⚖️ Medium Temperature (0.6)
"Shiver me timbers! This be a chest of gold fit for a king! Now who be havin' a key?"
(More personality, but still structured.)
🔥 High Temperature (1.0+)
"Blimey! It be a chest full o' socks! NOOO! The map was upside down again!"
(Completely chaotic and hilarious!)
I'm building a chaotic comedic pirate adventure, i think we all know which setting i'll be going with!
A quick recap
Okay, lets quickly review where we're at!We now have an AI agent thats convinced it's the most feared and legendary pirate to ever sail the seas. ✅
It can produce a believable and engaging story, with a mix of personality and structure. ✅
It can now consistantly follow the story structure and keep story lines and characters consistent. ✅
We have a way to monitor the overall token usage. ✅
We have a way to control the temperature of the output. ✅
Outputs are generally larger than 1200 tokens, which is a good start! ✅
Model stil defies daddys orders at giving an output of anything close to 4096 tokens! ❌
Txt Chunks n' Audio Chunks - The Departening!
Alright, another day another problem!With the model now consistantly outputting a good length of text, a new issues arises.
Turns out the OpenAI TTS (text to speach) API has a max input limit of 4096 Characters per request, which is aprroximately 5 minutes of audio.
(It's imporatnt to mention here, we are now talking about characters, NOT tokens)
Some of the journal entries are over 4096 characters, but some are not......
The ones that are over 4096 are getting automatically truncated when being passed to the TTS API.
This means, if a journal entry is over 4096 (Lets say for example we have a journal entry of 7000 characters) The TTS API will only pass the first 4096 characters to the API, generate the audio for that chunk, then just stop.
Giving you only 4096 characters of audio, and leaving the rest of the journal entry untold.
This is an issue...
Luckily this is a fairly simple problem to solve.
We know the limit for each TTS submission can max be 4096 characters, so we just need to split each journal entry into chunks of less than 4096 characters.
(Remembner we are now talking about characters, NOT tokens)
Alright, lets play it safe and split each journal entry into chucks of 4000 characters, this way we are sure we will not hit the limit.
This can easily be done by doing a some simple string manipulation in the code.
Some of the important things to consider however, is making sure the string split doesn't accour mid word, or mid sentence.
I found the best way to do this, was to make sure each split happened after a full stop.
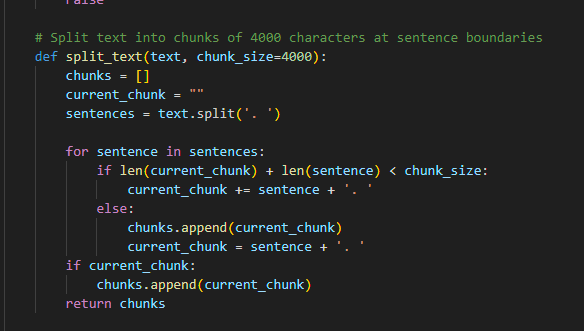
Okay great, we are now able to pass a full journal entry to the TTS API, without missing any data!
but rarely are things so simple......
Beacuase the text journal entries are being split into seperate chunks, and than fed to the TTS API in chunks of 4000 characters, this means the audio files outputted by the TTS API are also split into the same 4000 character chunks.
Now we find ourselves in the situation, were we can have up to 3 seperate audio files for one journal entry.
This is no good... The plan is to have a web series, were the audio files will be streamed directly from the website.
This should be seemless for the end user, and they should only have to deal with one audio file per episode.
Shit......
A small sidetrack for context
Okay, so at this point i knew i wanted to "stitch" the audio files together, but i had no idea how i was going to achieve this.I think this is a good point in the blog to tell you a little about myself.
I already mentioned i work in the IT industry, and have done for many years, but......
i'm not not a front end developer, i'm not a back end developer, and i'm certainly not a software engineer!
I work as a Cloud Architect, where my primary focus is designing and implementing cloud solutions inside Microsoft 365 and Azure.(These skills will will come into play later in the adventure, but for now, lets focus on the code.)
My standard day mainly consists of designing and maintaining IT infrastructure, with a large focus on cybersecurity and compliance.
This means i have a pretty good grasp of Powershell, and creating simple scripts to assist in my daily tasks, but Python, javascript, and HTLM is not an area i'm extremely well versed in.
I think this is important context to have for the upcoming sections of this blog.
Okay back to the problem at hand! - Stitching the audio files together.
Time to hit the "Google-fu" and see if i can find a way to achieve this!
During my time googleing for a solution, i came accross an intresting peice of software, that was about to change the game completely....
Cursor has entered the chat!

What is Cursor you ask?
Cursor is an AI-powered code editor designed to assist developers by integrating AI-driven coding features, such as autocompletions, debugging assistance, and smart code suggestions.
It is built as an AI-enhanced alternative to traditional code editors like VS Code and integrates with OpenAI's GPT models to help programmers write, refactor, and debug code faster.
Up until this point, i had been using VS Code (Which i really like) cursor is basicly VS code on steroids, with it's own brain.
This drasticly improved my workflow, and the speed at which i was able to generate code!
I went from spending a bunch of time googling Python syntax, debugging code, and trying to figure out the best way to do something, to just asking Cursor.
I was now an UNSTOPPABLE CODING MACHINE!
I know this is a touchy subject for many people.
Many people are understandably concerned about AI replacing jobs and impacting income. While those concerns are valid, what I will say is..."
If you are a front end devleoper, web developer, or anyone whos sepends most of their time in a IDE developing code.
If you are not uisng an AI assistant, you are wasting your time and your companies time!
Yes yes, i know this is a bold statement and this may trigger some people, belive me, i've had my fair share of internal battles on this topic.
I remember the early days of chatGPT.
I'd watch junior IT staff generating Powerscripts to solve smalll problems.
Back then it was 50/50 if the script even worked!
The Junior IT staff member had no freaking idea what the code did, how it worked, or what it could potentially do to the machine is was running on.
I always thought to myself "wow thats so dumb, you really don't learn anything from just generating code you don't understand"
I do still feel this way today, but with that being said, i think it comes down to how you use these tools.
If you are 100% reliant on an AI to generate all of your code (and you have no understanding of whats being displayed on your screen) your not going to learn anything.
However, if you refuse to embrace these tools, your competition will outpace you—becoming more efficient, more effective, and ultimately leave you behind.
I think i'll end this section with a quote from Charles Darwin.
"It is not the most intellectual of the species that survives; it is not the strongest that survives; but the species that survives is the one that is able best to adapt and adjust to the changing environment in which it finds itself"
Ummm, Jake, what about the audio files?
Oh yea, i almost forgot about that, things got a little bit deep back there didn't they?So umm yea.. I basicly just told Cursor, "Yo dawg, i got a problem with some audio files, wanna hook a brother up?"
Okay, thats not exactly how it happened.....
While googling for a solution, i found some information obout a python libary called "pydub" which could be used for manipulating audio files.
"Pydub is a Python library used for manipulating and processing audio files. It provides an easy-to-use API for loading, converting, trimming, merging, and applying effects to audio files without needing deep knowledge of audio processing."
With a little help from Cursor, i was able to whip some code together, and VOLIAAA, we now have a way to stitch audio files together!
No more part1.mp3, part2.mp3, part3.mp3, no more having to worry about the audio files being cut off mid sentence.
Lovely...
I would show you the code, but uuumm some stuff happened and i errrrr... don't have it anymore, but if i told you that now, we would be getting ahead of ourselves!
Early beginnings of the website
Oh yea, remember at the start of this blog i mentioned i was going to build the website from scratch?i think i mentioned .....
"Okay, heres what i'll do!
I'll whip up a quick HTML page, host it in an Azure static website, write some simple code, host the text episodes in a Azure blobs storage and voila!"
yeeaaaa..... we're only just getting to this part now!
Anyhow, I'll be hosting the website in an Azure static website (Suprise Suprise!)
Frist things first, lets Create a completely new Resource Group in Azure that will house all the resource we will use for this project.
RG-CaptainsLog - Check ✅
The astute amounst you may ask - "why are there so many things called "CaptainsLog"? and not "Captains Journal"? and why do you keep refering to "journal entries" as "log entries".
and to that i say - SHHHHHHH be patient, we'll get to that!
Okay resource group is deployed, now lets deploy the static website.
A few notes on the Azure Static Website. - It is completely Free, supports custom doamins, and even hosts a free SSL certificate.
Crazy Value! - I presume this is Microsofts way of getting people slowly onboard, and when their website explodes in popularity, their forced to move up to the paid teir.
However, there are a few limitations to be aware of in the free teir:
Bandwidth: There's a monthly data transfer limit of 100 GB.
Storage Capacity: Each app is limited to 250 MB of storage.
Custom Domains: You can configure up to 2 custom domains per app.
Staging Environments: The Free plan allows for 3 staging environments per app.
Service Level Agreement (SLA): The Free plan does not include an SLA, which means there's no guaranteed uptime or support.
For my use case, i'm not expecting any of these limitations to be an issue.
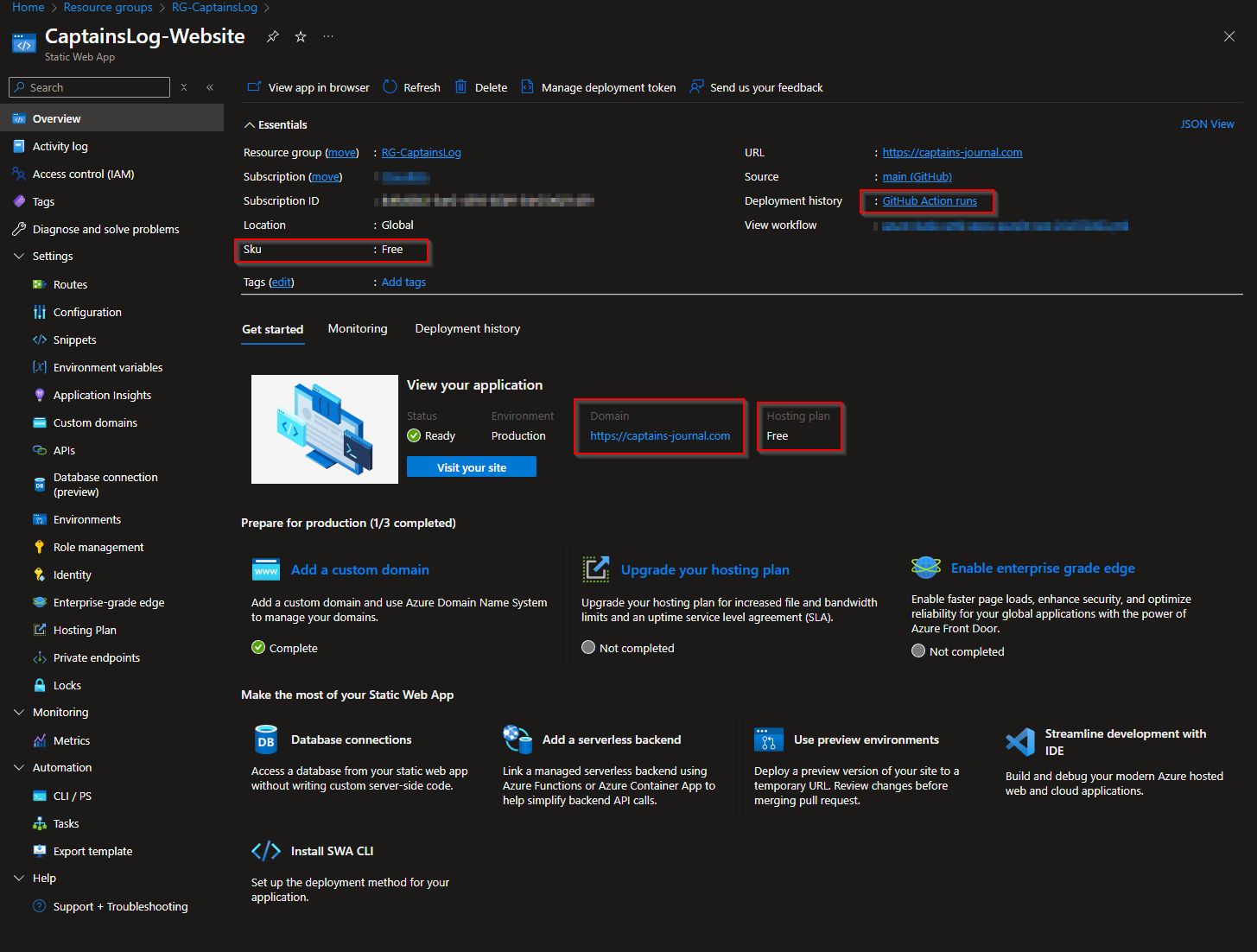
I choose to use Github Actions to deploy the static website.
This means i can push my code to my Github repository, and the Github Actions workflow will deploy the static website to Azure.
To put this in simple terms: Whenever i make any changes to my code, i can then "upload" the new code to my Github repository. Inside my Github repository there is a small "worker bot" that is constantly monitoring for new changes.
If the worker bot detects a new change, it will then trigger the Github Actions workflow and deploy the new changes to the static website.
The new code will then be displayed correctly on the website. - Nice and simple work flow!
Great! Now i need a custom domainname for the website, i'm thinking "Captainslog.com" - Yea you're allready ahead of me here right ?
SON OF A BITCH!
After alot of back and fourth brainstorming different name ideas, and constantly being disapointed by the fact the domain was already taken, i finally settled on "captains-journal.com"
I brought the custom domain, did some wizzardry with the DNS settings, and boom! We now have a website hosted on Azure!
Theres nothing on it, but we have a website!
The website vision
I knew exactly what i wanted for the website, wherever or not i could achive it, would be another matter.Heres what i had in mind:
Attractive visual design - Modern, clean, and responsive, with a clear pirate theme.
Simple layout - Easy to navigate, i didn't needs tons of different pages.
Smooth audio playback - Streaming of audio files directly from Azure Blob Storage, with an easy to use embedded audio player.
Subscribe Feature - I wanted users to be able to subscribe to the website, and receive email notification when a new episode is released.
Character bios - I've developed many characters for the series, it would be cool having some sort of character bio section, with AI generated art of my character designs.
Mobile Performance - I wanted the website to be mobile friendly, alowing users to listen to the episodes on the go.
100% autonomous - Episodes should be generated automatically on a set schedule, automatically upoaded to the azure blob storage and presentated ready for streaming on the website (Without any interaction from me)
When i realease this demon spawn to the world, it will be completely out of my hands!
Time to get to work!
With my secret weapon(Cursor), i was able to whip up a quick prototype for the website in no time at all.
Obviously the website went through many iterations, heres a little taster of one of the early iterations.
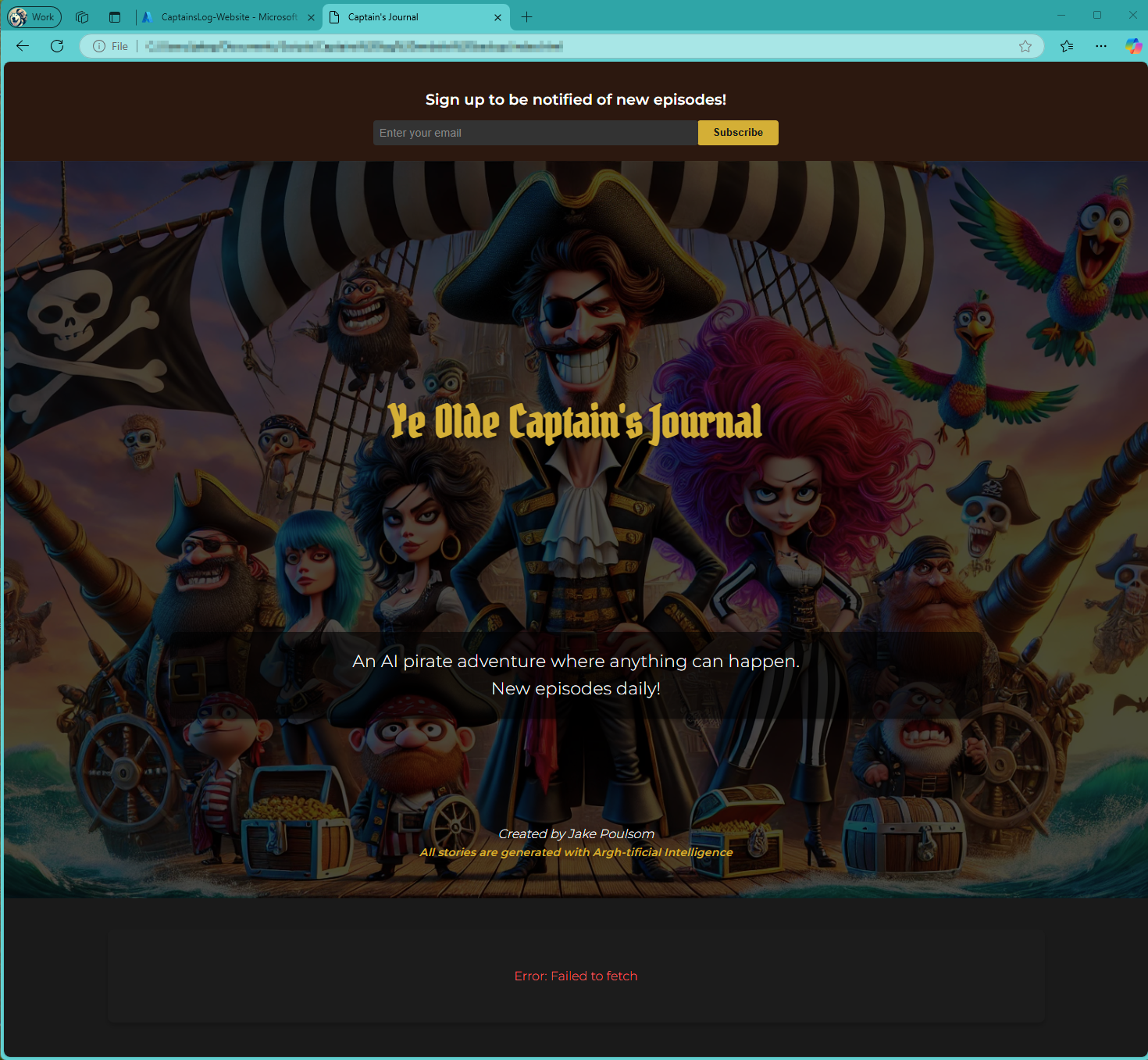
I feel like it improved alot since then, but i'll let you be the judge of that.
A quick recap of the AI Agent
Okay it's been a while since we last talked about the AI Agent, so i'll quickly recap what we have done so far.We have an AI Agent that belives it's the most feared and legendary pirate to ever sail the seas. ✅
The AI Agent can generate a believable and engaging story, with a mix of personality and structure. ✅
We have an AI Assitant that keeps track of the story and keeps the characters and their story archs consistent. ✅
We have a way to monitor our overall token usage. ✅
We have a way to control the temperature of the output. ✅
We have a way to split the journal entries into chunks of 4000 characters. ✅
We have a way to then stitch the audio files back together, outputting a single mp3 file. ✅
We still have a disobiedient model, that likes to defy daddys orders, and will never give an output of anything close to 4096 tokens. ✅
In a nutshell, we are able to run the script, each time the script runs it will generate a new journal entry which is a continuation of the previous entry.
I'm pretty happy with the progress on the AI Agent, so far. The stories it tells are quite entertaining, yet i'm still constantly changing my prompts to try and get the best possible results.
I'll probably be consistantly changing the prompts, right up until i go live with the first episode.
The one thing i'm not 100% happy with at the moment is the voice of the AI Agent.
I still haven't found the right voice to tell the story, but luckily this is not something that takes alot of code to change.
Okay, time to move the AI Agent to Azure - but what's an Azure Function?
An Azure Function is a serverless computing service that allows you to run small pieces of code (functions) in the cloud without managing a full server or infrastructure.
Think of it as "event-driven, auto-scaling code execution" in the cloud. It automatically scales, only runs when needed, and you pay only for what you use.
1️⃣ You write a function → A small piece of code that does a specific task.
2️⃣ It is triggered by an event → Example: HTTP request, file upload, database change.
3️⃣ Azure automatically runs the function when triggered.
4️⃣ It scales up or down automatically based on demand.
Oh and did i mention it's free?
Yes, there is a completely free teir for Azure functions! There are of course some limitations (some of which did create some extra headaches and extra work for me)
The Free Tier provides 1 million requests and 400,000 GB-seconds of resource consumption per month at no charge.
Again, AMAZING value! (I swear this is not sponsored by Microsoft, i'm not even sure they know i exist)
There are however a few caveats to be aware of with the free teir.
The Consumption Plan does not support VNet integration - This is not a deal breaker, it means intergrating with some Azure resources a little more difficult, but it does however support managed identity, so that helps.
"Cold Start Latency: Infrequently used functions may experience delays during startup, potentially impacting performance for time-sensitive applications"
This is the biggest issue with the free teir. It's not an issue with this particular function, but it will be a issue with some of the functions we build later.
Okay now we know what an Azure Function is, but why do i want to move my code there?
As i mentioned earlier, once the website goes live, i want everything to be completely autonomous.This means i want the AI Agent to be able to generate a new episode, upload it to the Azure Blob Storage, and update the website with the new episode.
All without any interaction from me.
We can achieve the first step of this plan by using a Time-Trigger in the Azure Function - Once we have moved the code into its new home, inside a cozzy Azure Function, we can set the function to run at a specific time each day.
This will however require quite a bit of modifcation to the existing code!
Remember, up until this point, the AI Agent was running on my local machine. This means it's always been generating files and saving them locally in the same folder as the script.
We now need to setup an Azure Storage Account and modify the code to save the files there instead of locally.
Nothing to fancy here, i'll just deploy the cheapest storage Account possible, LSR, general purpose V1, no zone redundancy or anything like that.
Inside the storage account, i'll create a new container called "captainslog" (yea, yea, this was actually before the whole domain name debacle, but fuck it, we are keeping the name now!)
Alright cool, we now have all of the infrastructure in place, we can now start to modify the code to save the files to the Azure Blob Storage instead of locally on my machine.
Okay, there are a few different ways we could do this, but I ended up using Access Keys to access the Azure storage account from the function.
Another cool thing about Azure Functions, is that they have support for enviroment variables - This means i can hide things like API keys, connection strings, and other sensitive information in the function app environment variables.
Which means i can Share the code with you guys!
Here's the full code for the AI Agent Function
from openai import OpenAI
from azure.storage.blob import BlobServiceClient
import azure.functions as func
import re
import logging
import os
from io import BytesIO
#Updated
client = OpenAI(
api_key=os.environ["OPENAI_API_KEY"]
)
# Initialize Azure Blob Storage client
connection_string = os.environ["AZURE_STORAGE_CONNECTION_STRING"]
blob_service_client = BlobServiceClient.from_connection_string(connection_string)
container_name = "captainslog" # Name of your container
container_client = blob_service_client.get_container_client(container_name)
def natural_sort_key(s):
"""Helper function to sort strings with numbers naturally"""
return [int(text) if text.isdigit() else text.lower()
for text in re.split(r'(\d+)', s)]
def main(mytimer: func.TimerRequest) -> None:
try:
logging.info('=== NEW FUNCTION EXECUTION STARTING ===')
# Initialize previous_logs list
previous_logs = []
# List all blobs in the container
logging.info("Starting to list blobs in container...")
all_blobs = list(container_client.list_blobs())
logging.info(f"Found {len(all_blobs)} total blobs in container")
for blob in all_blobs:
logging.info(f"Found blob: {blob.name}")
# Only get .txt files and sort them
log_files = sorted([blob.name for blob in all_blobs
if blob.name.startswith("Captains Log day") and
blob.name.endswith(".txt")],
key=natural_sort_key)
logging.info(f"Filtered to {len(log_files)} log files: {log_files}")
# Determine the next day number
next_day = 1 # Default to day 1 if no files exist
if log_files:
# Get the most recent log file
latest_log = log_files[-1]
logging.info(f"Latest log file found: {latest_log}")
# Extract the day number from the filename using regex
day_match = re.search(r"Captains Log day (\d+)\.txt", latest_log)
if day_match:
next_day = int(day_match.group(1)) + 1
logging.info(f"Extracted day number: {next_day-1}, next day will be: {next_day}")
else:
logging.warning(f"Could not extract day number from filename: {latest_log}")
raise ValueError("Invalid log file name format")
else:
logging.info("No existing log files found, starting with day 1")
logging.info(f"=== CONFIRMED: Generating log for day {next_day} ===")
# When saving files, double-check the day number
log_filename = f"Captains Log day {next_day}.txt"
audio_filename = f"Captains Log day {next_day}.mp3" # Simplified audio filename
# Verify the file doesn't already exist before proceeding
blob_client = container_client.get_blob_client(log_filename)
try:
blob_client.get_blob_properties()
logging.error(f"File already exists: {log_filename}")
raise ValueError(f"File already exists: {log_filename}")
except Exception as e:
if "BlobNotFound" in str(e):
logging.info(f"Confirmed file does not exist: {log_filename}")
else:
raise
# Read all previous logs if they exist
previous_logs = []
# Read all previous logs from Azure
for log_file in log_files:
blob_client = container_client.get_blob_client(log_file)
previous_logs.append(blob_client.download_blob().readall().decode('utf-8'))
Context = """
THIS IS WHERE THE SUPER AMAZING PIRATE PROMPT NORMALLY LIVES,
BUT CONTAINS MASSIVE CHARACTER AND STORY SPOILERS, SO I'VE REMOVED IT!
"""
# Get token counts for the context
context_tokens = client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "developer", "content": Context}],
max_tokens=1 # Minimal response to just get token count
).usage.prompt_tokens
logging.info(f"Context tokens: {context_tokens}")
# Track tokens for previous logs
previous_logs_tokens = 0
messages = [{"role": "developer", "content": Context}]
# Read all previous logs and count their tokens
for log_file in log_files:
blob_client = container_client.get_blob_client(log_file)
log_content = blob_client.download_blob().readall().decode('utf-8')
previous_logs.append(log_content)
messages.append({"role": "assistant", "content": log_content})
log_tokens = client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "assistant", "content": log_content}],
max_tokens=1
).usage.prompt_tokens
previous_logs_tokens += log_tokens
logging.info(f"Log entry tokens: {log_tokens}")
if previous_logs:
messages.append({
"role": "developer",
"content": "Please write the next journal entry, continuing the story from all previous logs while maintaining consistency in the story and character development. Do **not** stop early. If you feel the response is complete, keep expanding with more vivid descriptions, character thoughts, and action. Add extra detail, dialogue, and inner monologues if needed."
})
messages.append({
"role": "developer",
"content": "You MUST write a complete log entry using the full 4096 tokens. Do not stop early. Take your time, add more details, inner monologues, or setup for future events. Keep writing until you hit the token limit."
})
completion = client.chat.completions.create(
model="gpt-4-turbo",
store=True,
messages=messages,
max_tokens=4096,
stop=None,
temperature=0.8
)
ai_message = completion.choices[0].message.content
finish_reason = completion.choices[0].finish_reason # Get the finish reason
# Get output tokens count
output_tokens = client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "assistant", "content": ai_message}],
max_tokens=1
).usage.prompt_tokens
# Log token usage statistics - making it more visible with separate log entries
usage = completion.usage
logging.info("========== TOKEN USAGE STATISTICS ==========")
logging.info(f"Prompt Tokens: {usage.prompt_tokens}")
logging.info(f"Completion Tokens: {usage.completion_tokens}")
logging.info(f"Output Tokens: {output_tokens}")
logging.info(f"Total Tokens: {usage.total_tokens}")
logging.info(f"Previous Logs Tokens: {previous_logs_tokens}")
logging.info(f"Context Tokens: {context_tokens}")
logging.info(f"Finish Reason: {finish_reason}") # Log the finish reason
logging.info("===========================================")
logging.info(f"Successfully generated completion for day {next_day}")
except Exception as e:
logging.error(f"OpenAI API error: {str(e)}", exc_info=True)
raise
try:
# Save text to Azure
log_filename = f"Captains Log day {next_day}.txt"
blob_client = container_client.get_blob_client(log_filename)
blob_client.upload_blob(ai_message.encode('utf-8'), overwrite=True)
logging.info(f"Successfully saved text to blob: {log_filename}")
except Exception as e:
logging.error(f"Blob storage error: {str(e)}", exc_info=True)
raise
# Split text into chunks of 4000 characters at sentence boundaries
def split_text(text, chunk_size=4000):
chunks = []
current_chunk = ""
sentences = text.split('. ')
for sentence in sentences:
if len(current_chunk) + len(sentence) < chunk_size:
current_chunk += sentence + '. '
else:
chunks.append(current_chunk)
current_chunk = sentence + '. '
if current_chunk:
chunks.append(current_chunk)
return chunks
# Split text into chunks and process audio
try:
logging.info('Starting text chunk processing...')
text_chunks = split_text(ai_message)
logging.info(f'Successfully split text into {len(text_chunks)} chunks')
# Create a single audio file regardless of chunks
audio_filename = f"Captains Log day {next_day}.mp3"
combined_audio = BytesIO()
logging.info(f'Processing {len(text_chunks)} audio chunks...')
for i, chunk in enumerate(text_chunks):
try:
logging.info(f'Processing chunk {i+1} of {len(text_chunks)}')
speech_response = client.audio.speech.create(
model="tts-1",
voice="ash",
input=chunk
)
# Append this chunk's audio data to our combined buffer
combined_audio.write(speech_response.content)
except Exception as e:
logging.error(f"ERROR processing audio chunk {i+1}: {str(e)}", exc_info=True)
raise
# Reset buffer position to start
combined_audio.seek(0)
# Upload the single combined audio file
blob_client = container_client.get_blob_client(audio_filename)
blob_client.upload_blob(combined_audio.getvalue(), overwrite=True)
logging.info(f"Successfully saved combined audio to blob: {audio_filename}")
logging.info('Audio processing completed successfully')
try:
# Log text response details
logging.info(f"Text response length: {len(ai_message)}")
logging.info(f"Text saved to Azure as {log_filename}")
except Exception as e:
logging.error(f"Error logging text details: {str(e)}", exc_info=True)
# Don't raise here, continue to function completion
try:
# Function completion message
logging.info('Python timer trigger function completed successfully')
return # Explicitly return from the function
except Exception as e:
logging.error(f"Error in final logging: {str(e)}", exc_info=True)
# Don't raise here, let function complete
except Exception as e:
logging.error(f"Critical error in audio processing: {str(e)}", exc_info=True)
raise
Oh yea, remember way back when, when I had the issues with the audio files, and getting them stiched together ? and I mentioned it would be a problem later ?
Well turns out the that Pydub (which was the libary i was using to stiche the audio files together), requires FFmpeg to be installed to work.
Of course this didn't exsist within my Azure Function, so when i first migrated everything, i had a bunch of errors and couldn't understand why the script kept crashing.
Turns out, this was the issue.
Thats why i ended up changing to BytesIO, which turned out to be a much better solution.
BytesIO is a file-like object in Python that allows you to read and write binary data in memory (RAM) instead of a physical file.
This is much more efficient and faster than using a physical file, so it actaully turned out to be a blessing in disguise.
Okay recap time again!
We now have the code for the AI Agent inside an Azure Function, the function is triggered by a Time-Trigger, which means it will run at a specific time each day.
The function will then generate a new episode, save the .txt file from the output, and the .mp3 file to the Azure Blob Storage.
Perfect, we are making progress!
Now we just need create a container on the website, which will house the audio player, and to figure out how to automcatailly update the website whenever a new episode is avaialble in the blob storage.
HTTP Triggers - Making me want to pull the trigger on myself
This next section, was by far the most difficult part of the whole project.I knew what HTTP Triggers were, but i had never worked with them before, again, i'm not a web developer, so this was a fairly new concept for me.
This combined with my pathetic lack of knowledge when it comes to javascript, ment this was gunna be a real challenge.
For this all to work seemlessly, i needed HTML, Python, javascript, HTTP Triggers and a whole lot of trial and error!
Luckily for me, i had my two new best friends at the ready! - ChatGPT and Cursor!
Okay, time to tackle the first step, getting any episodes in the blog container, to be streamable on the site, and all new episodes to be added to the site automatically.
Azure Function - Loading the Episodes
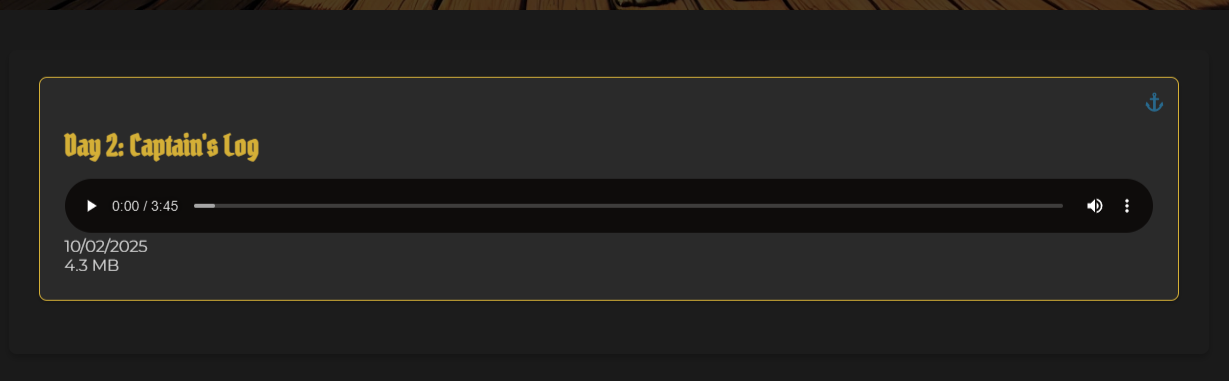
Okay this step will consist of a few different working parts.Firstly, i will need to create the HTML code for the episodes container on the website.
This will be the area where the each epeisode will be loaded, and the embeded audio player will be loaded for each episode.
The HTML Code
<!-- Main Content -->
<div class="content-wrapper">
<div class="episode-container" id="episodeContainer">
<article
class="loading-container"
id="loadingSpinner"
style="display: none"
>
<div class="pirate-ship">
<img
src="/images/pirate-ship.svg"
alt="Loading animation - Pirate ship"
/>
</div>
<p class="loading-text">Loading the Captain's Log...</p>
</article>
<div id="errorContainer" class="error-container" role="alert"></div>
<div id="episodeContainer" role="feed" aria-label="Episodes list"></div>
<nav id="paginationContainer" aria-label="Episodes pagination"></nav>
<!-- Episodes will be dynamically inserted here -->
</div>
</div>
I also created a mega cute little pirate ship, which is a little animation that will play.
This serves as a placeholder for when no episodes are available, or when episodes are loading.
Obviously, this also consisted of a bunch of css work in the styles.css file, and a bit of javascript to make the animaiton of on the ship.

God dam it's so cute and charming, this might be my favorite part of the entire website!
Anyhow, now we need to create some Javascript to make a HTTP request to an Azure Function, requesting any available episodes.
The JavaScript Code
async function fetchEpisodes(page = 1, itemsPerPage = 10) {
console.log(`Fetching episodes for page ${page} with ${itemsPerPage} items per page`);
const loadingSpinner = document.getElementById('loadingSpinner');
const errorContainer = document.getElementById('errorContainer');
const episodeContainer = document.getElementById('episodeContainer');
const paginationContainer = document.getElementById('paginationContainer');
try {
if (loadingSpinner) loadingSpinner.style.display = 'block';
if (errorContainer) errorContainer.style.display = 'none';
const functionUrl = AZURE_FUNCTION_URL;
console.log('Making API request...');
const response = await fetch(functionUrl);
if (!response.ok) throw new Error(`HTTP error! status: ${response.status}`);
const data = await response.json();
console.log(`Received ${data.blobs?.length || 0} episodes from API`);
if (!data.blobs || !Array.isArray(data.blobs) || data.blobs.length === 0) {
if (episodeContainer) {
episodeContainer.innerHTML = `
<div class="loading-container">
<div class="pirate-ship">
<img src="/images/pirate-ship.svg" alt="Loading..." />
</div>
<div class="loading-text">New episodes coming soon! ☠️</div>
</div>
`;
}
if (paginationContainer) {
paginationContainer.innerHTML = '';
}
return;
}
// Sort episodes
const episodes = data.blobs.sort((a, b) => {
const dayA = parseInt(a.name.match(/day (\d+)/i)[1]);
const dayB = parseInt(b.name.match(/day (\d+)/i)[1]);
return dayB - dayA;
});
}
}And finally we have the Azure Function that will handle the request!
The Azure Function Code
const { BlobServiceClient, StorageSharedKeyCredential, generateBlobSASQueryParameters, BlobSASPermissions } = require('@azure/storage-blob');
module.exports = async function (context, req) {
context.log('Function starting - testing blob storage connection');
try {
const connectionString = process.env.AZURE_STORAGE_CONNECTION_STRING;
const containerName = process.env.CONTAINER_NAME;
// Parse connection string to get account name and key
const accountName = connectionString.match(/AccountName=([^;]+)/)[1];
const accountKey = connectionString.match(/AccountKey=([^;]+)/)[1];
const sharedKeyCredential = new StorageSharedKeyCredential(accountName, accountKey);
const blobServiceClient = BlobServiceClient.fromConnectionString(connectionString);
const containerClient = blobServiceClient.getContainerClient(containerName);
const blobs = [];
for await (const blob of containerClient.listBlobsFlat()) {
if (blob.name.toLowerCase().endsWith('.mp3')) {
const blobClient = containerClient.getBlobClient(blob.name);
// Generate SAS token for this blob
const startsOn = new Date();
const expiresOn = new Date(new Date().valueOf() + 3600 * 1000); // 1 hour from now
const sasOptions = {
containerName: containerName,
blobName: blob.name,
permissions: BlobSASPermissions.parse("r"), // Read only
startsOn: startsOn,
expiresOn: expiresOn,
};
const sasToken = generateBlobSASQueryParameters(
sasOptions,
sharedKeyCredential
).toString();
// Construct URL with SAS token
const sasUrl = `${blobClient.url}?${sasToken}`;
blobs.push({
name: blob.name,
url: sasUrl, // Use the SAS URL instead of the direct blob URL
size: blob.properties.contentLength,
lastModified: blob.properties.lastModified
});
}
}
context.res = {
status: 200,
headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*'
},
body: {
message: "Successfully retrieved blobs",
blobCount: blobs.length,
blobs: blobs
}
};
} catch (error) {
context.log.error('Function failed:', error);
context.res = {
status: 500,
headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*'
},
body: {
error: 'Function failed',
message: error.message,
timestamp: new Date().toISOString()
}
};
}
};
Okay, at this point your probably thinking, "how the fuck does this work?"
Well, let me explain.
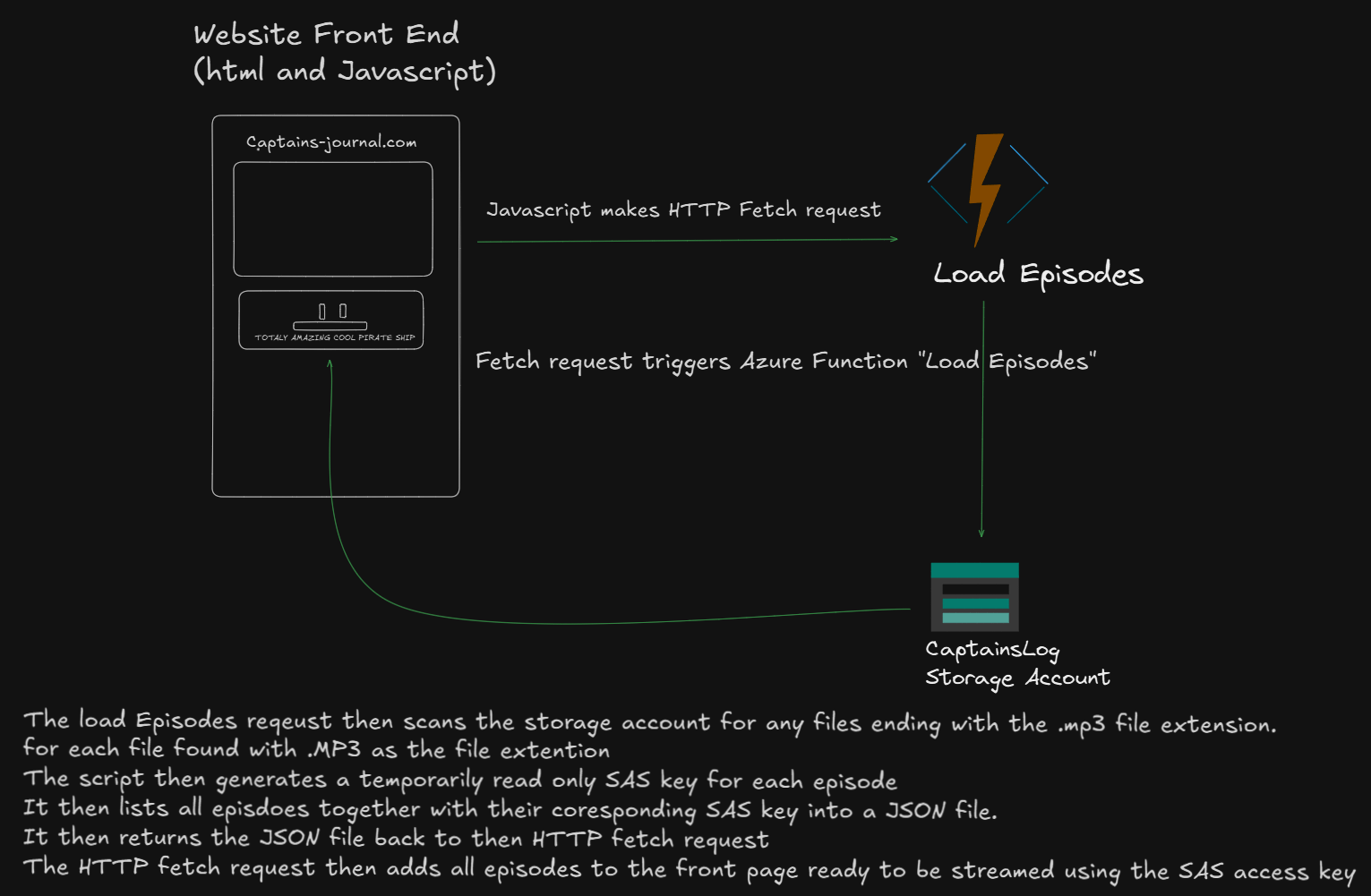
So with this method, as soon as .mp3 file is available in the blob storage, the media player will automatically update and display the new episode ready for streaming!
Azure Function - The Subscribe Feature
Okay, at this point i'm almost 2 weeks deep into this project.What went from being a quick "in out adventure" into the world of AI Agents, has now turned into a full blown project. Consuming all of my free evenings, and weekends.
I'm obsessed, and i need to bring this project to fruition!
However, if i'd had known how much work this was about to become, for such a minor feature (That probablly barely anyone will use), i'd had probably just had left it out.
I'm not going to lie, this was a royal ball ache to get working!
But, i'll be honest, i'm glad i went through with it, because it was a great learning experience, and i'm sure there are a few people who will use it.
So lets break it down.
We need some sort of a "sign up" form on the website.
We then need some way of storing emails in a database.
Then we need a way of monitoring the blob storage for new episodes.
If a new episode is found in blob storage it should trigger 2 functions.
1. The function we have already built, that loads the episdoes to the website.
2. A new function that emails all emails addresses in the database, informing them that a new episode is available.
Step 1 - Storing users Emails in a database
Okay firstly we create a nice looking subscription form, matching the style of the rest of the website.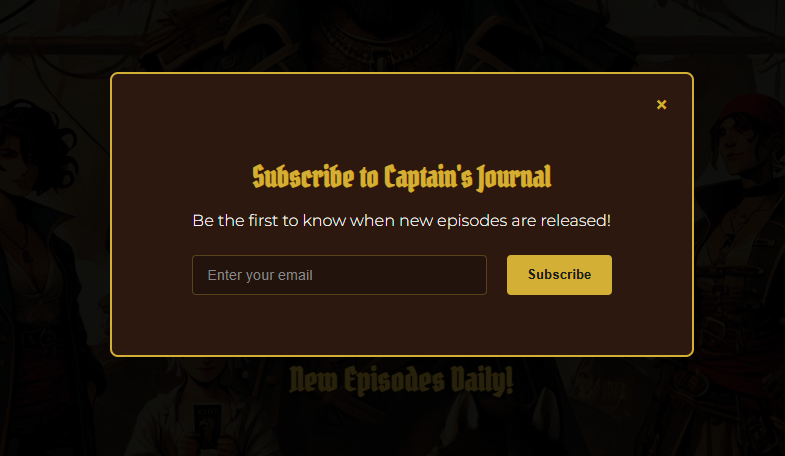
Then we create some Javasrcipt to handle the form submission.
Along with some error handling, to give the user feedback on their submission.
For example: We need to make some simple checks like, is the email already in the database, is the input in a valid email address format etc.
// Single form submission handler
emailForm.addEventListener('submit', async function(e) {
e.preventDefault();
const email = document.getElementById('emailInput').value;
const submitButton = emailForm.querySelector('button[type="submit"]');
try {
submitButton.disabled = true;
submitButton.textContent = 'Subscribing...';
errorDiv.textContent = '';
errorDiv.className = 'error-message';
const response = await fetch('AZURE_FUNCTION_URL', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ email })
});
const data = await response.json();
if (response.status === 200) {
errorDiv.textContent = 'Thank you for subscribing! 🏴☠️';
errorDiv.className = 'error-message success';
emailForm.reset();
setTimeout(closeModal, 2000);
} else if (response.status === 400 && data.error === 'Email already exists in database') {
errorDiv.textContent = 'You are already signed up! ⚓';
errorDiv.className = 'error-message warning';
} else {
errorDiv.textContent = 'Failed to subscribe. Please try again.';
errorDiv.className = 'error-message error';
}
} catch (error) {
console.error('Subscription error:', error);
errorDiv.textContent = 'A problem occurred. Please try again later.';
errorDiv.className = 'error-message error';
} finally {
submitButton.disabled = false;
submitButton.textContent = 'Subscribe';
}
});
function closeModal() {
modal.style.display = 'none';
document.body.style.overflow = 'auto';
emailForm.reset();
errorDiv.textContent = '';
errorDiv.className = 'error-message';
}
My original plan for the storing the email addresses was to use an Azure SQL database, but that would actually be overkill for this project.
So instead I ended up using Azure table storage, which is a much simpler and cheaper solution.
I created a table in the exsisting azure storage account, and then created a new function to handle the requests.
const { TableClient, odata } = require("@azure/data-tables");
module.exports = async function (context, req) {
context.log('Starting email subscription process...');
try {
// Enable CORS
context.res = {
headers: {
'Access-Control-Allow-Credentials': 'true',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'POST, OPTIONS',
'Access-Control-Allow-Headers': 'Content-Type',
}
};
// Handle preflight requests
if (req.method === 'OPTIONS') {
context.res.status = 204;
return;
}
// Validate request
const email = req.body && req.body.email;
if (!email) {
throw new Error('Email is required');
}
// Connect to Table Storage
const tableClient = TableClient.fromConnectionString(
process.env.STORAGE_CONNECTION_STRING,
"Subscribers"
);
// Check if email already exists
try {
await tableClient.getEntity("subscribers", email.toLowerCase());
// If we get here, the email exists
context.res = {
status: 400,
headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*'
},
body: {
error: 'Email already exists in database'
}
};
return;
} catch (error) {
// If error is "not found", continue with subscription
if (error.statusCode !== 404) {
throw error;
}
}
// Create entity
const entity = {
partitionKey: "subscribers",
rowKey: email.toLowerCase(),
email: email,
dateAdded: new Date().toISOString()
};
// Add to table
await tableClient.createEntity(entity);
context.res = {
status: 200,
headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*'
},
body: {
message: 'Subscription successful'
}
};
} catch (error) {
context.log.error('Detailed error:', {
message: error.message,
stack: error.stack,
name: error.name
});
context.res = {
status: 500,
headers: {
'Access-Control-Allow-Origin': '*',
'Content-Type': 'application/json'
},
body: {
error: error.message || 'Failed to process subscription'
}
};
}
};
The function also does a few pre flight checks, to make sure the email is valid, and that it doesn't already exist in the database.
If these checks pass, the function will add the email to the table, under the "subscribers" partition key, and add a timestamp to the record.
Awesome users now have the ability to subscribe to the Captain's Journal!
Creating the unsubscribe feature
Okay, now that we have given people the ability to subscribe, we also need to give them the ability to unsubscribe.If i'm going to be doing daily releases, people might get fed up of getting emails everyday, so it's only fair they have the option to unsubscribe.
Basicly, we just need to build a new function, that does the apposite of the subscribe function we just built.
Instead of adding an email to the database, it will search for a specific email in the database, if it finds the email, it will remove it from the database.
However, there is a small caveat.
This can't be a button on the website, or a trigger from the website. It has to be a link inside the email end users recieve, when a new episode goes live.
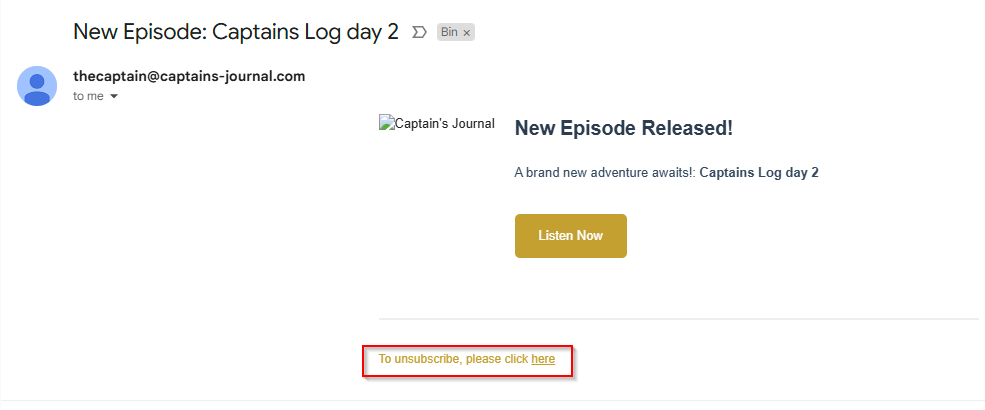
We're using another Azure function to send this email (which we'll get to in a moment) but here's a snippet of the part of the code, that actually creates the email and the link inside the email.
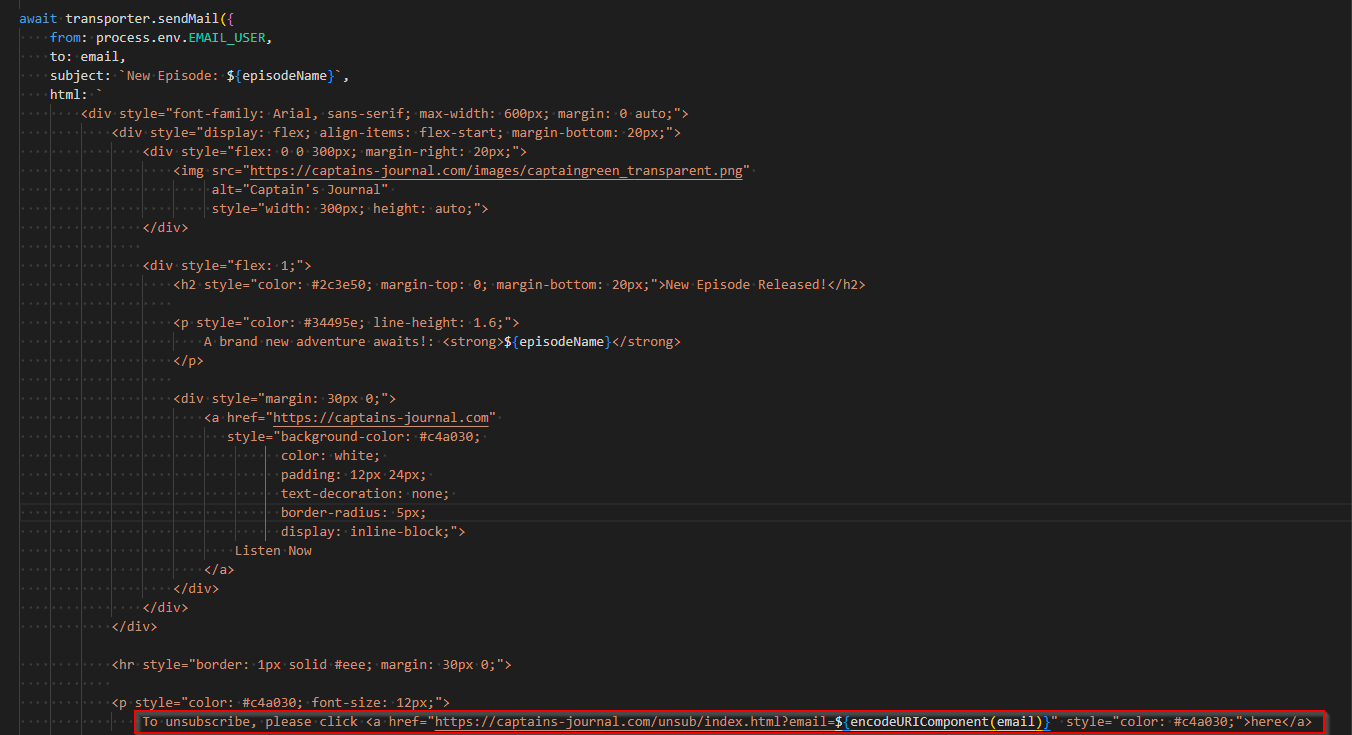
So how does this work?
The important thing to take note of here, is the link in the buttom of the code.
Take note of the (EncodeURIComponent(email)) part.
What this does is, it encodes the email address of the user that clicked the link, into the actual link itself.
When the user clicks the link, it redirects the user to https://captains-journal.com/unsub - Navigating to this page normally will do nothing.
However, navigating to the page with a encoded email address in the URL, will trigger a small script.
document.addEventListener("DOMContentLoaded", async () => {
const urlParams = new URLSearchParams(window.location.search);
const email = urlParams.get("email");
const messageDiv = document.getElementById("message");
console.log("Email from URL:", email);
if (!email) {
messageDiv.textContent = "Invalid unsubscribe link - no email provided";
messageDiv.className = "message error";
return;
}
try {
const apiUrl = `https://app-func-captainslog.azurewebsites.net/api/UnsubscribeEmail?email=${encodeURIComponent(email)}`;
console.log("Calling API:", apiUrl);
const response = await fetch(apiUrl, {
method: "GET",
headers: {
Accept: "application/json",
"Cache-Control": "no-cache",
},
});
console.log("Response status:", response.status);
const responseText = await response.text();
console.log("Response text:", responseText);
let data;
try {
// Only try to parse JSON if we have a response
if (responseText) {
data = JSON.parse(responseText);
} else {
throw new Error("Empty response from server");
}
} catch (parseError) {
console.error("Failed to parse JSON:", parseError);
throw new Error(
`Server response error: ${responseText || "No response"}`
);
}
if (response.ok) {
messageDiv.textContent = `You have been successfully unsubscribed from the Captain's Journal newsletter.`;
messageDiv.className = "message success";
} else {
messageDiv.textContent =
data?.error || "Failed to unsubscribe. Please try again later.";
messageDiv.className = "message error";
}
} catch (error) {
console.error("Error:", error);
messageDiv.textContent = `Error: ${error.message}`;
messageDiv.className = "message error";
}
});
This script will then trigger the Azure unsubscribe function, passing on the encoded email address within the link.
The Azure function will then scan the database for the email address, if the email address is found, it will be removed from the database.
The Unsubscribe Function
import logging
import azure.functions as func
from azure.data.tables import TableServiceClient
from azure.core.exceptions import ResourceNotFoundError
import json
import os
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('UnsubscribeEmail function triggered')
headers = {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*"
}
try:
email = req.params.get('email')
logging.info(f'Processing unsubscribe request for email: {email}')
if not email:
return func.HttpResponse(
body=json.dumps({"error": "Email parameter is required"}),
headers=headers,
status_code=400
)
# Connect to table storage
connection_string = os.environ["AZURE_STORAGE_CONNECTION_STRING"]
table_service = TableServiceClient.from_connection_string(connection_string)
table_client = table_service.get_table_client("subscribers")
try:
# Use the known partition key and email as row key
partition_key = "subscribers"
row_key = email
logging.info(f'Attempting to delete entity with PartitionKey: {partition_key}, RowKey: {row_key}')
# Delete the entity
table_client.delete_entity(
partition_key=partition_key,
row_key=row_key
)
logging.info(f'Successfully deleted entity for email: {email}')
return func.HttpResponse(
body=json.dumps({
"message": "Successfully unsubscribed",
"email": email
}),
headers=headers,
status_code=200
)
except ResourceNotFoundError:
logging.warning(f'No subscription found for email: {email}')
return func.HttpResponse(
body=json.dumps({
"error": "Email not found or already unsubscribed"
}),
headers=headers,
status_code=404
)
except Exception as e:
logging.error(f'Table operation error: {str(e)}')
return func.HttpResponse(
body=json.dumps({
"error": f"Failed to process unsubscribe request: {str(e)}"
}),
headers=headers,
status_code=500
)
except Exception as e:
logging.error(f'Error: {str(e)}')
return func.HttpResponse(
body=json.dumps({
"error": f"Internal server error: {str(e)}"
}),
headers=headers,
status_code=500
);
The function then passes the result back to the script, which then displays a message to the user, informing them that they have been unsubscribed from the newsletter.
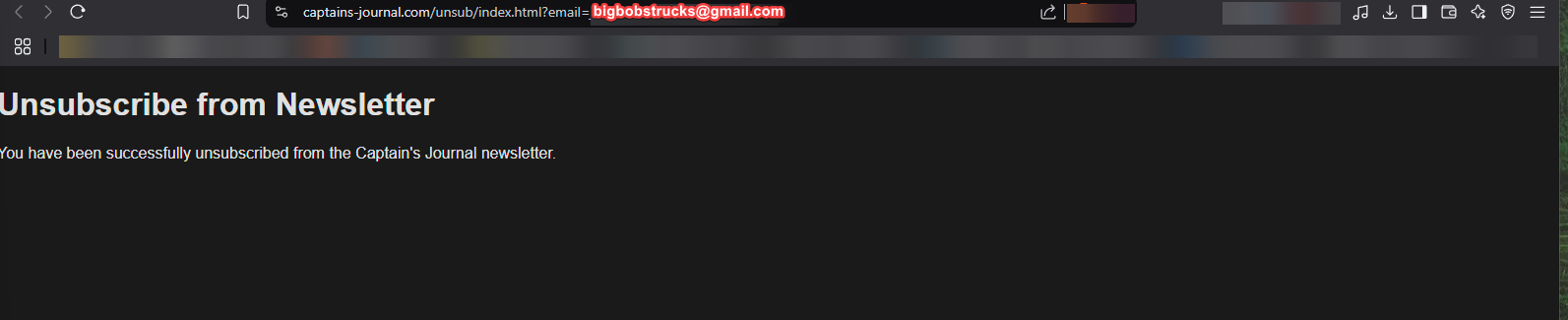
This is the part that really broke me. There are so many moving parts to this, and everything has to work in sync, or it wont work.
but oh boy does it feel good watching it work like a well oiled machine!
Sending Emails when a new episdoe goes live
Okay, we're almost there! Time for the final peice of the puzzle!We need to create a Function that will send an email to all users in the database when a new episode goes live.
This part was actually surprisingly simple.
Turns out, Azure functions have a built in trigger called a "Blob Trigger".
This trigger is used to trigger a function when a new blob is created in the storage account
(Or in our case, when a new episode is created).
Basicly, we just write a simple script that triggers when a new item is created in the blob storage, the script then checks if it's a .mp3 file.
if the new blob is a .mp3 file, the script then sends an email to all email addresses in the database informing them that a new episode is available.
The Blob Trigger Function
const { TableClient } = require("@azure/data-tables");
const nodemailer = require("nodemailer");
module.exports = async function (context, myBlob) {
context.log("Blob trigger function processed blob:", context.bindingData.name);
try {
// Only process .mp3 files
if (!context.bindingData.name.toLowerCase().endsWith('.mp3')) {
context.log('Not an MP3 file, skipping...');
return;
}
// Get all subscribers from Table Storage
const tableClient = TableClient.fromConnectionString(
process.env.STORAGE_CONNECTION_STRING,
"Subscribers"
);
const subscribers = [];
const iterator = tableClient.listEntities();
for await (const entity of iterator) {
subscribers.push(entity.email);
}
context.log(`Found ${subscribers.length} subscribers`);
// Configure email transport for Microsoft 365
const transporter = nodemailer.createTransport({
host: "smtp.office365.com",
port: 587,
secure: false, // true for 465, false for other ports
auth: {
user: process.env.EMAIL_USER, // Your Microsoft 365 email
pass: process.env.EMAIL_PASS // Your Microsoft 365 password or app password
},
tls: {
ciphers: 'SSLv3'
}
});
// Send emails to all subscribers
const episodeName = context.bindingData.name.replace('.mp3', '');
for (const email of subscribers) {
// ... (keep all the code the same until the sendMail part) ...
// ... (keep all the code the same until the sendMail part) ...
// ... (keep all the code the same until the sendMail part) ...
await transporter.sendMail({
from: process.env.EMAIL_USER,
to: email,
subject: `New Episode: ${episodeName}`,
html: `
INSIDE THIS AREA OF THE SCRIPT IS THE HTML CODE FOR THE EMAIL, WHICH I SHOWED IN THE PREVIOUS SECTION.
I CAN'T DISPLAY IT IN THIS PREVIEW SINCE THE PREVIEW IS SET TO JUST DISPLAY THE JAVASCRIPT CODE.
THE SCREENSHOT WITH THE (EncodeURIComponent(email)) LINK
// ... (keep the rest of the code the same) ...
// ... (keep the rest of the code the same) ...
// ... (keep the rest of the code the same) ...
context.log(`Email sent to ${email}`);
}
context.log('All notification emails sent successfully');
} catch (error) {
context.log.error('Error processing blob trigger:', error);
throw error;
}
};
We have a fully automated system that sends emails to all users in the database when a new episode goes live!
Testing testing and more testing
WOW! I made it - I finally built this thing!An entire tech stack, but the question is, does everything work?
Amazingly enough, YES! Everything seems to be working flawlessly.
There is only one issue i've noticed so far!
If you recall way back when i first talked about fuctions, i mentioned some of the caveats of using the free tier of Azure functions
Namely, "Cold Start Latency: Infrequently used functions may experience delays during startup, potentially impacting performance for time-sensitive applications"
This is definitely noticable with regards to the function that loads the episodes to the site. Sometimes it can take up to 30 seconds to display the episosdes....
It's not because the website is slow, it's simplely because the function is "sleeping" and it takes a few seconds to wake up.
(Doesn't this inherantly just mean the website is actaully slow?)
SHUT UP FUTURE JAKE!!!!!! WHO IS ONLY HERE BEACAUSE HE HAS TO PROOF READ THIS ENTIRE GOD DAM BLOG!!!!!!
Other than this, the majourity of my time spent testing, has been generating stories, testing different prompts, styles and AI settings.
Oh, and experimenting with epicly themed pirate voices, narrated by yours truely! (Wink Wink)
This is without a doubt the most important part of the entire project!
If the story and charcacters are not fun/entertaining, and i can't control the AI Agent from going completely rouge, the entire website, the Azure functions, the AI agent, and the absurde amount of time i spent on that stupid subscriber function, exsists for nothing.
PLEASE FOR THE LOVE OF GOD, SOMEONE PLEASE SUBSCRIBE, JUST ONE PERSON, JUST LET ME SEE THAT SWEET PROCESS RUN ONCE!!
Ahhhhh... i digress, I will be spending the next few days trying to get this as dialed in as best as possible. I want to bring you guys the best pirating squash buckeling adventure, ye land lubbers could ever ask for...FOR I AM NOT CALLED CAPTAIN ADMIRAL FANCYBOOTS THE THIRD FOR NOTHING!!
HMMPHEE *Cough Cough" *Clears throat* *Cough Cough* - sorry, i'm not quite sure what happened there...
Anyhow, on to some housekeeping...
Housekeeping
Now that the website is built, there is a few housekeeping things I need to take care of.Creating a personal email adddress for the captain
Being a Microsoft 365 guy, and since everything is allready hosted in Azure, the logical option here is to just create a new email address using Microsoft 365.So i added the "captains-journal" domain to my M365 tenant, and created the email address thecaptain@captains-journal.com
Gave the account an exchange online license, and we're good to go!
Had a few issues with emails ending up in spam folders when i tested with some personal accounts, so i ended up fixing SPF, DKIM, and DMARC for the domain, which will hopefully sort that out.
This will be the email address used to send out the notifications when a new episode goes live.
Feel free to use this e-mail address to contact me if you have any questions, or just want to say hi!
Meta data - Website tweaks
The next part of the housecleaning process was adding all the meta data to the website.Nothing really exciiting here, but feel it's worth mentioning, since it's pretty important these days.
Just simple stuff like - If a user links the site in a whatsapp group, or a facebook/instagram post, it displays the correct image, title, description etc.
Just trying to make things look a bit more professional, and help with SEO.
I'll also spend some time making a few tweaks, making sure performance is good, and maybe, just maybe, i'll get around to building that character bios page i mentioned a while back.
Function keys
This ones a big one.A lot of the functions i built when testing, used function keys which were visable in pain text in the client side javascript.
This is a big no-no, so i'll need to fix this before i go live.
It's not really a big security concern, given the content of my website, and the functions i'm using, but it could be a big conern for my wallet!
If someone got access to my functions, they could potentially just constantly call the funcitons, sending API calls to OPENAI and creating runs in Azure, which could ultimately end up costing me a lot of money!
Ethier way, i'm doing things right, so that will be fixed before launch! <
The final chapter - Doubt.....
It's time, i can't run from it any longer, it's time to release the website to the rest of the world.What a weird feeling......
I've been so consumed by this for weeks now, the thought of openly putting my work out to the public is a scary one.
Some people know i've been working on something, but nobody has actually seen anything - It's been my own little secret getaway.
It's a strange combination of excitment and anxiety. I'm excited to see peoples reactions, but on the other hand, i'm nervous about the feedback i'll get.
I guess this is only natural when you've been working on something for a while, and it's finally time to let it out into the wild.
But yet, i can't shake certain doubts....
What if the first episode the AI generates is completely wild, and it goes completely off the rails?- If the first episode is bad, it's not going to bring people in.
Will the website suddenly crash and burn if it starts to get a lot of traffic?
Is there something critcal i've overseen?
Did i leave sensitive information visable in code?
Will people even care?
But then i remind myself how this all started.....
I didn't build this to impress anyone. I didn't build this for my CV, and I certainly didn't build this to make a quick buck. It all stemmed from a simple curiosity about AI Agents—just a spark of an idea that grew into something bigger than I ever expected.
Along the way, I've learned so much, not just about AI and building things, but about the process of creating something from nothing. And the best part? This is just the beginning. I already have a ton of ideas for future projects, and I can't wait to explore them.
Oh, and to circle all the way back to the start of this blog… YUP!! SAS is most definitely in trouble. AI Agents are going to change the game.
But for now, i've rambled on long enough—it's time to actually do it.
If you've made it this far, thank you.
I hope you've enjoyed reading this blog, and maybe, just maybe, my journey will inspire you to build something of your own—just like Microsoft CEO interview inspired me.
Every great adventure starts with uncertainty, and every captain has to take that first step onto the deck, not knowing what the seas ahead may bring.
So, here we go. The anchor is up, the wind is in the sails, and The Captain's Journal is officially setting course for the world.
I hope you'll come aboard and join me on this journey. Let's see where the tide takes us. ⚓🏴☠️
